1. vanilla k8s-deployed cassandra cluster 한계
기반 지식 없이 관리하기 어렵고 운영상 이슈들도 다루기 힘들 수 있습니다.
(Cassandra k8s node drain후 새로운 노드 cluster join 불가 이슈, 데이터 유실 이슈, 전체 데이터 적재 중 cassandra 파드 무한 재시작 이슈 등등..)
1.1. Vanilla k8s-deployed vs cass-operator deployed cassandra cluster
Vanilla Kubernetes가 배포한 카산드라 클러스터의 장점:
- 유연성: 더 많은 제어 및 사용자 지정 옵션을 제공
- 확장성: Vanilla Kubernetes를 사용하면 필요에 따라 Cassandra 클러스터를 확장하거나 축소할 수 있으므로 변화하는 워크로드에 쉽게 조정가능
- 휴대성: Vanilla Kubernetes 배포는 클라우드 provider와 온프레미스 인프라 간에 이동이 가능하므로 필요한 경우 Cassandra 클러스터를 다른 환경으로 쉽게 이동할 수 있음
Vanilla Kubernetes가 배포한 카산드라 클러스터의 단점:
- 복잡성: 쿠버네티스에서 카산드라 클러스터를 처음부터 설정하는 것은 복잡하고 시간이 많이 걸리는 프로세스일 수 있으며, 카산드라와 쿠버네티스 모두에 대한 심층적인 지식이 필요
- 유지관리: operator 도움 없이 업그레이드, 백업 및 모니터링을 포함하여 Cassandra 클러스터의 모든 유지 보수 작업을 처리해야 함
Cass-operator가 배포한 카산드라 클러스터의 장점:
- 단순성: Cass-operator는 카산드라 클러스터 설정 및 유지관리와 관련된 많은 복잡하고 시간이 많이 걸리는 작업을 자동화하여 배포 및 운영이 더 쉬워짐
- 사용 편의성: 간단한 Kubernetes 매니페스트를 사용하여 Cassandra 클러스터를 정의할 수 있으므로 배포 및 관리가 더 쉬워짐 + 선언적인 관리
- 향상된 신뢰성: 많은 일상적인 작업을 자동화하여 사용자 오류의 위험을 줄이고 카산드라 클러스터의 신뢰성을 향상시킴.
Cass-operator가 배포한 카산드라 클러스터의 단점:
- 제한된 유연성: Cass-operator는 Vanilla Kubernetes 배포에 비해 배포에 대한 컨트롤을 적게 제공하여 사용자 지정 옵션을 제한함.
- Vendor lock-in: operator 기반 배포는 일반적으로 특정 공급업체 또는 오픈 소스 프로젝트와 연결되므로 필요한 경우 다른 operator 또는 배포 방법으로 전환하기가 어려움.
2. cass-operator deployed cassandra cluster
2.1. cass-operator
- crd, cr을 k8s에 배포합니다. Kubernetes에서는 CRD를 인식할 수 있고, CR 인스턴스가 생성되면 상태를 저장할 수 있습니다.
- cass-operator를 배포합니다. (Operator)
- cassandraDatacenter 오브젝트를 메니페스트를 이용해 정의하여 생성합니다.
- cass-operator는 이 오브젝트의 lifecycle, operator에 구현된 추가 로직 등을 통해 관리합니다.
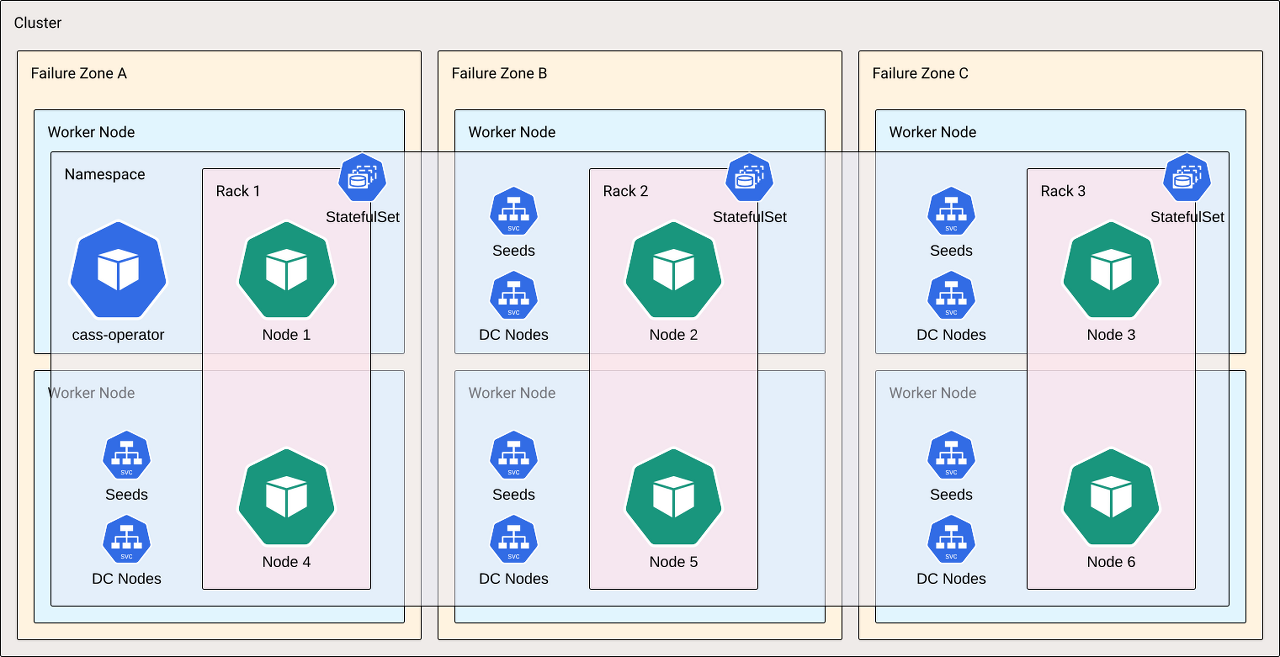
1 개의 datacenter, 3개 rack, 6개 worker node == 1개 ns, 3개 statefulsets, 6개 Pod
즉, 아래와 같이 대응됩니다.
- datacenter == namespace
- rack == statefulset
- node == pod
Kubernetes에서는 각 Cassandra pod가 여러 개의 컨테이너로 구성됩니다. Cassandra pod에서 실행되는 첫 번째 컨테이너는 server-config-init initContainer입니다. 이 컨테이너는 CassandraDatacenter custom resource의 입력을 기반으로 각 pod 당 구성을 렌더링하는 역할을 합니다.
그 후, 메인 어플리케이션 컨테이너가 시작됩니다.
Cassandra pod에는 항상 두 개의 어플리케이션 컨테이너 'cassandra'와 'server-system-logger'가 포함됩니다. cassandra 컨테이너는 즉시 Cassandra를 시작하지 않습니다. 대신, Apache Cassandra의 management API가 처음으로 시작됩니다.
이는 cass-operator에 의해 요청될 lifecycle, operation tasks를 위한 REST API를 부트스트랩합니다.
2.2. Detail Advantage
1. 클러스터 관리 간소화: Cass-Operator는 Kubernetes에서 Cassandra 클러스터를 관리하는 단순화된 방법을 제공하여 클러스터 관리의 많은 복잡성을 추상화하고 관리자가 애플리케이션에 집중할 수 있도록 합니다.
2. Resilience(복원력) 향상: Cass-Operator는 클러스터 복구 및 자가 복구를 위한 기본 제공 메커니즘을 제공하므로 개별 노드에 장애가 발생하더라도 클러스터가 계속 정상적으로 작동하도록 보장할 수 있습니다.
3. 성능 향상: Cass-Operator는 컨테이너화된 환경에서 Cassandra를 실행하도록 최적화되었으며 최고의 성능을 제공하도록 설계되었습니다.
4. 향상된 확장성: Cass-Operator는 필요에 따라 클러스터를 확장하거나 축소할 수 있는 사용하기 쉬운 툴을 제공하므로 관리자는 애플리케이션이 증가함에 따라 용량을 쉽게 추가하거나 제거할 수 있습니다.
5. 다른 도구와의 통합: Cass-Operator는 DSE(DataStax Enterprise)와 같은 DataTax에서 제공하는 다른 도구 및 서비스와 통합되어 Cassandra 클러스터를 관리하고 최적화하기 위한 추가적인 기능을 제공합니다.
2번을 자세히 살펴보자.
- Self Healing: Cass-Operator는 클러스터에서 장애가 발생한 노드를 자동으로 감지하여 교체합니다. 노드에 장애가 발생하면 operator는 장애를 감지하고 장애가 발생한 노드를 교체할 새 pod를 실행합니다. 이렇게 하면 개별 노드에 장애가 발생하더라도 클러스터가 계속 정상적으로 작동할 수 있습니다.
- Recovery 메커니즘: Cass-Operator는 장애로부터 복구하기 위한 다음과 같은 몇 가지 메커니즘을 제공합니다:
- Node replacement: 노드에 장애가 발생하면 operator는 장애가 발생한 노드를 교체하기 위해 새 pod를 실행합니다. 이렇게 하면 개별 노드에 장애가 발생하더라도 클러스터가 계속 정상적으로 작동할 수 있습니다.
- Rolling upgrades: Cass-Operator는 Cassandra 클러스터의 롤링 업그레이드를 수행하기 위한 도구를 제공하여 다운타임을 최소화하고 소프트웨어 업그레이드 중에도 클러스터가 계속 정상동작하도록 보장합니다.
- 데이터 Repair: Cass-Operator는 개별 노드에 장애가 발생하더라도 클러스터의 데이터가 일관되고 정확하게 유지되도록 지원하는 Cassandra data repair 도구를 제공합니다.
- Rebalancing: Cass-Operator는 Cassandra 클러스터의 데이터 balance를 재조정하기 위한 도구를 제공합니다. 노드가 추가되거나 제거되더라도 클러스터의 노드에 데이터가 고르게 분산되도록 합니다.
2.3. kubernetes operator pattern
Kubernetes Operator 패턴 개념을 사용하면 Controller를 하나 이상의 Custom Resource 에 연결하여 Kubernetes 자체의 코드를 수정하지 않고도 클러스터의 동작을 확장할 수 있습니다. Operator는 Custom Resource의 Controller 역할을 하는 Kubernetes API의 클라이언트입니다.
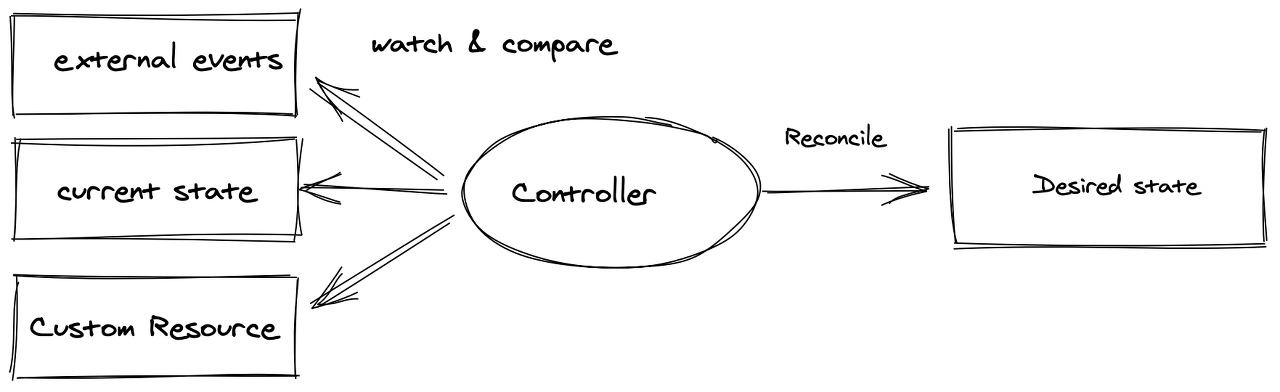
Controller는 감시 대상 object를 관찰하며 reconcile 루프를 사용하여 desired state를 current state와 지속적으로 비교합니다. (*Controller가 오류를 업그레이드하거나 해결하는 방법과 같은 추가적인 작동 지식을 가지고 있는 경우 Operator로 분류하곤 합니다.)
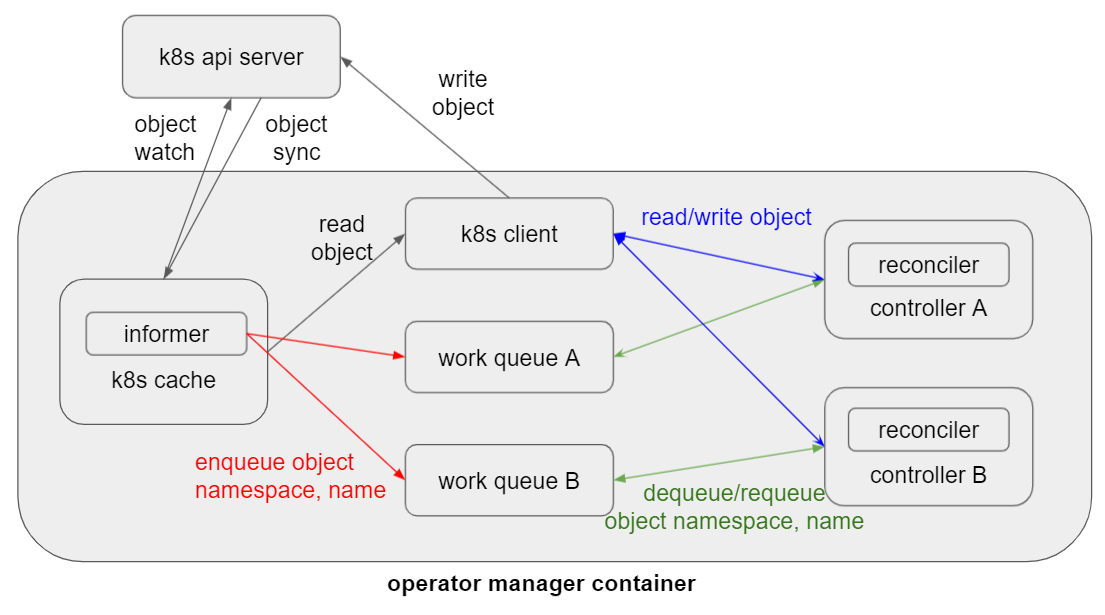
아래와 같이 k8s api server의 부하를 줄여주기 위해 operator manager는 k8s cache를 갖습니다. k8s client를 가진 operator는 api server로 오브젝트 write 요청을 보내지만, read요청은 모두 k8s cache로부터 이루어집니다. informer는 object를 k8s api server로부터 watch, sync 하며 이벤트를 받습니다.
받은 정보는 namespace, name 정보뿐이며 이를 controller마다 존재하는 work queue에 enqueue합니다. 이후, 각 controller의 reconciler는 queue에서 object namespace, name을 꺼내와 desired state로 맞추는 작업을 실행합니다. 실패할 경우 다시 work queue로 넣고 성공할 때까지 dequeue/enqueue 를 반복합니다.
3. cassandra operator로 배포하기
3.1 살펴보기 전 k8s-deployed vanilla cassandra cluster 참고 사항
| 언제 token range가 변경되나? → 노드 추가, 삭제시 백그라운드에서 수행. Apache Cassandra에서 노드의 token range는 노드가 추가되거나 제거될 때와 같이 클러스터가 token ring movement를 겪을 때 변경됩니다. 노드의 token range는 노드가 저장 및 제공하는 partition key values의 range를 나타냅니다. 클러스터가 변경되면 데이터가 고르게 분산되고 모든 노드가 계속 올바르게 작동하도록 노드의 토큰 범위를 업데이트해야 합니다. 이 업데이트 프로세스는 카산드라에 의해 자동으로 수행되며, 클러스터의 새로운 상태를 반영하기 위해 token range를 다른 노드에 재할당하는 작업이 포함됩니다. token range 변경은 일반적으로 클러스터 작업에 미치는 영향을 최소화하면서 백그라운드에서 원활하고 투명하게 처리됩니다. |
| k8s-deployed cassandra cluster 에서 언제 token range가 변동되는 예시 Kubernetes가 배포한 Apache Cassandra 클러스터에서 한 pod가 작동 중단되고 새 pod로 교체되면 기존의 persistent volume 이 새 pod에 연결됩니다. 카산드라는 자동으로 pod 교체를 감지하고 부트스트랩 프로세스를 수행하여 클러스터에 조인합니다. 부트스트랩 프로세스 중에 새 노드는 이전 노드에 저장된 데이터의 복사본을 수신하고 업데이트된 클러스터에서 새 token range가 할당됩니다. 데이터가 클러스터의 모든 노드에 고르게 분산되도록 다른 노드의 token range도 업데이트할 수 있습니다. 즉, Kubernetes가 배포한 Apache Cassandra 클러스터의 pod가 다운되어 교체될 때, 데이터가 고르게 분산되도록 새 노드와 클러스터의 다른 노드의 token range가 변경될 수 있습니다. |
| bootstrap이 실패하면? 부트스트랩 프로세스가 실패하고 Kubernetes가 배포한 Apache Cassandra 클러스터의 새 노드가 중단되면 클러스터가 일관성이 없거나 사용할 수 없게 될 수 있습니다. 새 노드가 이전 노드에 저장된 데이터의 복사본을 수신할 수 없는 경우 불완전하거나 오래된 정보가 있을 수 있으며, 이는 클러스터의 전반적인 성능과 안정성에 부정적인 영향을 미칠 수 있습니다. 또한 새 노드에 token range가 할당되었지만 클러스터에 제대로 join할 수 없는 경우 해당 데이터가 클러스터에 제대로 통합되지 않아 불일치가 발생하고 데이터 손실이 발생할 수 있습니다. 부트스트랩 프로세스가 실패하고 노드에 장애가 발생할 경우 가능한 한 빨리 문제를 진단하고 해결하여 클러스터 작업의 중단을 최소화하는 것이 중요합니다. 장애의 세부 사항에 따라 클러스터를 복구하고 기능을 복원하려면 수동 작업이 필요할 수 있습니다. |
| replaceNode 시나리오로 문제 해결하기 K8sandra의 "replaceNode" 시나리오는 kubernetes에 배치된 카산드라 클러스터의 노드를 교체하는 과정을 말합니다. replaceNode 시나리오는 일반적으로 노드에 장애가 발생하거나 업데이트가 필요한 경우에 필요합니다. 이 프로세스에는 다음 단계가 포함됩니다: 1. 새 노드 만들기: k8ssandra operator를 사용하여 새 카산드라 노드를 만드는 것으로 시작합니다. 이 노드는 장애가 발생했거나 오래된 노드를 교체하는 데 사용됩니다. 2. 이전 노드를 해제합니다: 데이터를 클러스터의 다른 노드로 보내어 이전 노드의 권한을 해제합니다. 이 작업은 카산드라 nodetool을 사용하여 수행할 수 있습니다. 3. 데이터를 새 노드로 이동합니다: 이전 노드에 저장된 데이터를 새 노드로 이동합니다. 이 작업도 nodetool로 가능합니다. 4. 클러스터 업데이트: 노드의 변경 사항을 반영하도록 카산드라 클러스터를 업데이트합니다. 이 작업도 nodetool로 가능합니다. 5. 클러스터 유효성 검사: 클러스터가 올바르게 작동하고 데이터가 올바르게 복제되고 있는지 확인합니다. k8sandra operator를 사용하여 카산드라 클러스터의 노드를 쉽게 교체할 수 있으며, 클러스터가 최신 상태를 유지하고 효율적으로 작동하도록 보장합니다. 2번에서 내부적으로 '-Dcassandra.replace_address_first_boot=' 옵션이 적용됩니다. Apache Cassandra의 "-Dcassandra.replace_address_first_boot=" 옵션은 노드가 성공적으로 부트스트랩할 수 없을 때 클러스터에 join할 수 있도록 하는 데 사용됩니다. 일반적인 부트스트랩 프로세스에서는 새 노드가 클러스터에 연결되어 클러스터의 다른 노드로부터 데이터를 수신하기 시작합니다. 그러나 이 프로세스가 실패하면 노드가 클러스터에 가입하지 못할 수 있습니다. 이러한 경우 "-Dcassandra.replace_address_first_boot=" 구성 옵션을 사용하여 새 노드가 대체할 클러스터의 기존 노드 주소를 지정할 수 있습니다. 새 노드가 이 구성 옵션으로 시작하면 지정된 노드에 연결하여 자신의 주소를 새 노드의 주소로 바꾸도록 요청합니다. 이렇게 하면 새 노드가 클러스터에 가입하고 다른 노드에서 데이터를 수신하기 시작할 수 있습니다. "-Dcassandra.replace_address_first_boot=" 옵션은 노드에 장애가 발생하여 교체해야 하는 경우에 특히 유용합니다. 클러스터에서 정상 노드의 주소를 지정하면 부트스트랩을 성공적으로 수행할 수 없는 경우에도 새 노드가 클러스터에 가입하여 데이터 수신을 시작할 수 있습니다. 결론적으로, "-Dcassandra.replace_address_first_boot=" 구성 옵션은 클러스터에 있는 기존 노드의 주소를 지정하여 부트스트랩을 성공적으로 수행할 수 없을 때 새 노드가 카산드라 클러스터에 가입할 수 있는 방법을 제공합니다. 이렇게 하면 개별 노드에 장애가 발생하더라도 클러스터가 계속 정상적으로 작동할 수 있습니다. |
'DB' 카테고리의 다른 글
| Cassandra Operator (0) | 2022.11.24 |
|---|---|
| Cassandra Consistency Level (0) | 2022.11.15 |
| Cassandra 기본 (0) | 2022.09.14 |

